This post originally appeared on the 7digital developer blog on 15th February 2011. It has been moved here for preservation.
A few weeks ago, we launched the shiny, redesigned new 7digital.com to a beta audience. Unfortunately, we had a memory leak.
The new site was hosted on the same set of hardware as a few other applications, and it was gradually bringing the other sites down. We put a limit on the amount of virtual memory to shield the other sites from the memory leak, but performance kept deteriorating. Thankfully, the memory leak was eventually found – here’s a set of steps I followed to find it.
Step 1: Take a memory dump from the live site
Graham, a fellow dev, helpfully pointed out userdump and also gave me a crash course in windbg. Userdump is a command line tool which will take a snapshot of the memory space used by a process. It’s important to note that it freezes your process while it takes the dump, so if you’re doing this in live, your site might stop for a minute or more. You can use the inbuilt iisapp.vbs script on the command line to find out exactly which w3wp process belongs to which Application Pool, and therefore which process to dump. Once you have the process id, take the memory dump and examine it with windbg. Two useful articles were Getting Started with windbg by JohanS, and Tess Ferrandez’s excellent lab/tutorial on how to navigate through a memory dump.
Step 2: Add some performance counters
Since the live dump didn’t highlight any obvious problems (it only had information for a minute or less of runtime before the app pool recycled), we added some performance counters to see if we could find any trends. You can access perfmon under Start > Administrative Tools > Performance. MSDN has a good explanation of the different counters and what they mean. Since we were concentrating on memory, I added the following counters and waited for any trends to appear.
.NET CLR Exceptions\#Exceps thrown
.NET CLR Memory\#Bytes in all Heaps
.NET CLR Memory\Gen 2 Heap Size
.NET CLR Memory\Large Object Heap Size
Edit: It’s possible to show counters for a single process, but if you have multiple w3wp processes running on the same box (as we do), it’s difficult to get the counters for the right one. I was looking at counters for the whole box, which didn’t give me a lot of detail.
Step 3: Do some local profiling
A live memory dump is all well and good, but it just looks like a screen full of hex 🙂 Local profiling gives you some lovely graphs, stack traces, statistics on running time, etc which you can use to drill down into specific methods or lines of code. If you know what user action is causing the leak (e.g. clicking the “Purchase” button), you can profile that on your local machine and easily identify which method or line of code is causing the problem.
I downloaded ANTS Memory Profiler, DotTrace, and AQTime to try some local profiling. The learning curve on ANTS seemed to be the gentlest, although if you are familiar with any of the tools, it would help greatly. The ANTS inline help files were an excellent refresher course on how .NET garbage collection works.
Step 4: Local profiling with load testing
I spent about a day learning how ANTS works, and doing some common page loads on my local machine. I didn’t see anything unusual. But…. my mistake was to profile without load. It’s very difficult to spot trends unless the changes being made by an action are exaggerated.
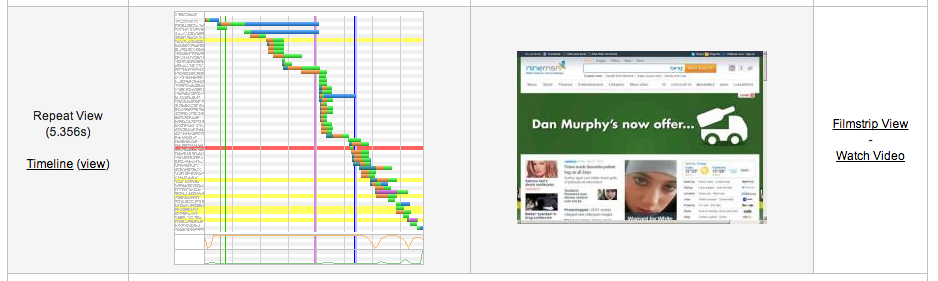
ApacheBench was recommended, which is a command line tool for benchmarking performance, but also handy for making lots of concurrent requests. So I lined up multiple requests (and executed them multiple times, all while running ANTS) for common pages in our site, like the search page, artist page and album page. Nothing really turned up until I tried to add products to a basket – and got my breakthrough. Here are the two graphs of memory usage from ANTS. The first shows code behaving itself and being cleaned up by the garbage collector when some normal actions were load tested. The second illustrates our memory leak – the line in green highlights the total memory (managed + unmanaged) being used by our process, the line in red is the amount of managed memory allocated by .NET. Unforunately, this meant that our leak was in unmanaged memory, which ANTS couldn’t help me track down.
Good memory profile:

Bad memory profile:

Step 5: Finding unmanaged memory leaks
So, back to the dump taken from the live site with userdump. James Kovacs has written a helpful article which, among other things, lists reasons why you might be leaking unmanaged memory. I took another memory dump with more user activity to examine, and had a look at the assemblies in the app domain. Along with the usual suspects:
Assembly: 034a3fd8 [C:\WINDOWS\Microsoft.NET\Framework\v2.0.50727\Temporary ASP.NET Files\b\970be4ca\1a5ec57f\assembly\dl3\139d25740cf5f9d_99b8cb01\Lucene.Net.dll]
ClassLoader: 034a4048
SecurityDescriptor: 034a3d18
Module Name
04ac1d74 C:\WINDOWS\Microsoft.NET\Framework\v2.0.50727\Temporary ASP.NET Files\b\970be4ca\1a5ec57f\assembly\dl3\139d25740cf5f9d_99b8cb01\Lucene.Net.dll
....
There were an enormous number of dynamic assemblies being loaded into our app domain:
Assembly: 286ff688 (Dynamic) []
ClassLoader: 286ff6f8
SecurityDescriptor: 286ff600
Module Name
0062429c Dynamic Module
0062461c Dynamic Module
This was the reason that the memory kept increasing. Some piece of code was dynamically loading assemblies, and once there, they never get unloaded. However, it’s very difficult to get any more information about them in windbg for framework version 2.0. Windbg for v2.0 has less commands than windbg for v1.1 (strange!), and the internet seems to be full of demos using windbg 1.1 showing more information than you get now. They are a good starting point, but be aware you won’t be able to follow them 100%. Tess Ferrandez again has a great tutorial on chasing down unmanaged memory leaks if dynamic assemblies aren’t your problem.
Step 6: Local debugging
The Modules window in Visual Studio shows you which assemblies have been loaded, and it gives you more information than windbg (the name of the assembly, at least) so it was just a matter of repeating the step that caused the error with the debugger attached, and watching when the number of assemblies changed. The culprit was finally found – it was the Application_Error event handler. We were mis-using a piece of 3rd party code which was creating dynamic assemblies every time an error occurred. And unfortunately for us, it was a catch-22 because our beta users were finding errors we’d missed in testing, making the leak worse.
Step 7: Verification Profiling
We fixed the offending code, and then re-profiled with ApacheBench to verify that the memory was no longer leaking. The whole process took almost three days to track down and fix, mostly because I hadn’t managed to isolate what action was causing the leak. Once I started load testing, the leak was much easier to identify. I was amazed at the number of tools and apps used when trying to find the leak, mostly to rule things out in a process of elimination. Quite satisfying once found, though 🙂