In December last year, the ABC launched a new video encoding system called Metro (“Media Transcoder”), which converts various sources of media into a standardised format for iview.
It’s been a fantastic project for the ABC’s Digital Network division – we’ve built a cheap, scalable, cloud-based solution that we can customise to suit our specific needs.
Metro has been live for a month, successfully transcoding thousands of pieces of content. Here’s an overview of how it’s been designed and what it does.
Background
Our previous transcoding system had a fairly straightforward job: produce the same set of renditions for each piece of content it was given. Both input and output files were fairly standardised. The previous system was convenient, but there were some aspects we couldn’t customise, and we didn’t use its #1 proposition: on-demand transcoding. Most of the content the ABC publishes is available to us days in advance, so we just need to make sure that it’s transcoded before it’s scheduled for release online.
We calculated that we could replace the existing system for less than the previous system cost, and take advantage of AWS services and their scalability. Other systems like the BBC’s Video Factory have been successfully built using the same model. Writing our own system would allow us to start batching up jobs to process in bulk, or use different sized instances to help reduce costs in the long term.
Our first step was to replicate what the existing system did, but allow it to scale when needed, and shut down when there’s nothing to do.
Architecture
Metro is a workflow pipeline that takes advantage of queues, autoscaling compute groups, a managed database, and notifications. Logically, the pipeline follows this series of steps: File upload > Queue Job > Transcode > Transfer to CDN > Notify client
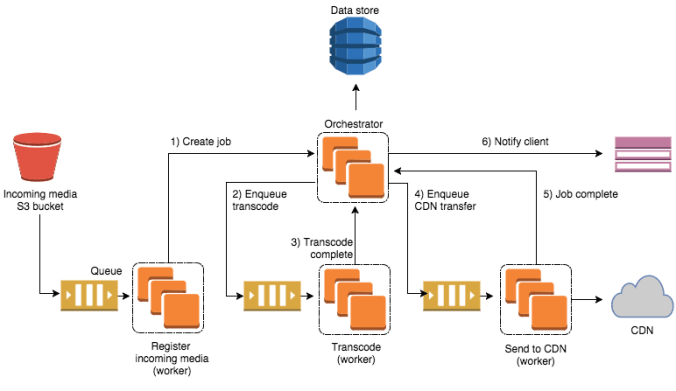
The pipeline is coordinated by the “Orchestrator”, an API written in node.js that understands the sequence of steps, enqueues messages, talks to our database, and tracks where each job is in the system. It’s also responsible for scaling the number of transcoding boxes that are processing our content.
Each step in our pipeline is processed by a small, isolated program written in Golang (a “queue listener”), or a simple bash script that knows only about its piece of the pipeline.
We are able to deploy each piece independently, which allows us to make incremental changes to any of the queue listeners, or to the Orchestrator.
Interesting bits
Autoscaling the Transcoders
The transcoders are the most expensive part of our system. They’re the beefiest boxes in the architecture (higher CPU = faster transcode), and we run a variable number of them throughout the day, depending on how much content is queued.
Before a piece of content is uploaded, we check to see how many idle transcoders are available. If there are no spare transcoders, we decide how many new ones to start up based on the transcoding profile. Higher bitrate outputs get one transcoder each; lower bitrates and smaller files might share one transcoder over four renditions. Once we process everything in the queue, we shut down all the transcoders so that we’re not spending money keeping idle boxes running.
Here’s a snapshot of the runtime stats (in minutes) on boxes over a 4 hour window:
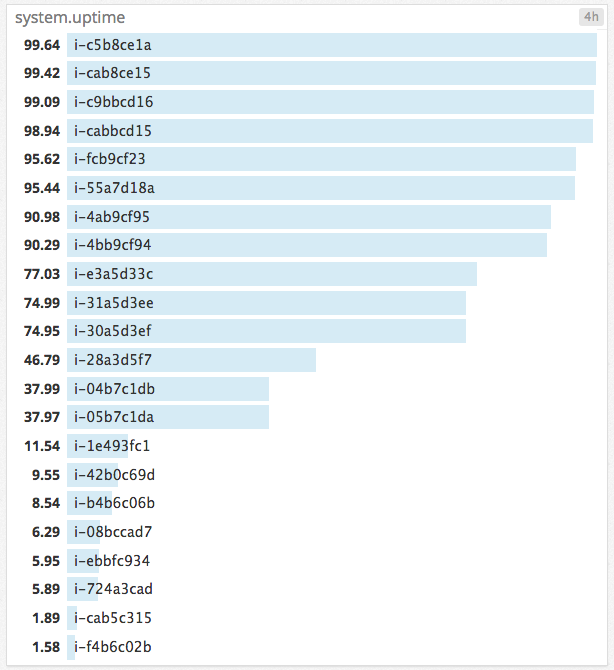
There’s definitely some optimisation we can do with our host runtime. In future, we’d like to optimise the running time of our transcoders so that they run for a full hour, to match Amazon’s billing cycle of one hour blocks. We’d also like to take advantage of Amazon’s spot instances – using cheaper computing time overnight to process jobs in bulk.
FFmpeg
FFmpeg is the transcoding software we use on our transcoders. It’s open source, well maintained, and has an impressive list of features. We’re using it to encode our content in various bitrates, resize content, and add watermarks. We create an AMI that includes a precompiled version of FFmpeg as well as our transcoder app, so that it’s ready to go when we spin up a new box.
There’s still a way to go before we’re using FFmpeg to its full extent. It’s capable of breaking a file into even chunks, which would make it perfect to farm out to multiple transcoders, and likely giving us even faster, consistent results every time. We can also get progress alerts and partial file download (e.g taking the audio track only, avoiding downloading a bunch of video information that you won’t use).
SQS Queues
We utilise SQS queues to keep our pipeline resilient. We’ve got different queues for various step in our system, and each queue has a small app monitoring it.
When a new message arrives, the app takes the message off the queue and starts working. If an error occurs, the app cancels its processing work and puts the message back at the head of the queue, so that another worker can pick it up.
If a message is retried a number of times without success, it ends up in a “Dead Letter Queue” for failed messages, and we get notified.
Things seem to be working well so far, but we’d like to change the queues so that consumers continually confirm they’re working on each message, rather than farming out the message and waiting until a timeout before another consumer can pick it up.
In Production
Metro has been transcoding for a month, and is doing well. Our orchestrator dashboard shows all of the jobs and renditions in progress:

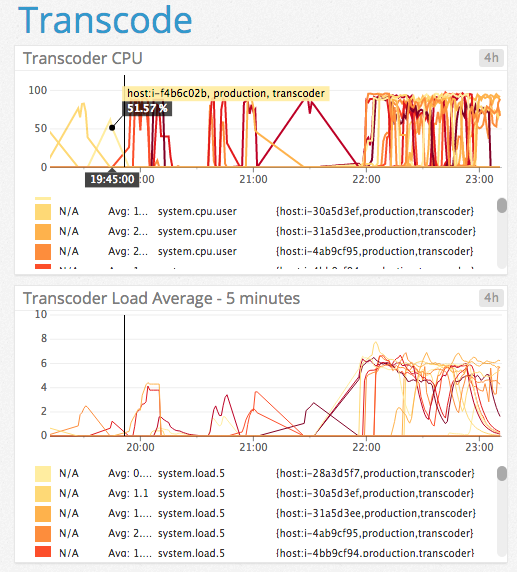
And some of the work done by transcoders in a 4 hour window:
The Future
We have more features to add, such as extracting captions, using cheaper computing hardware in non-peak times, and building priority/non-priority pipelines so that content can be ready at appropriate times. Metro has been really interesting to build, much cheaper than our previous solution, and we can customise features to suit our needs. I’m really looking forward to where it goes next.